DevOpsの一歩先へ!これなら営業も
ダッシュボードを見て判断する文化を作れる

- 株式会社アトラス
- 所在地東京都港区南青山1丁目15-9 第45興和ビル 9F
- 設立1986年
- 業種情報サービス業
- https://www.atlas.jp/
株式会社アトラスは「研究者が研究に専念できる世界へ」を理念に、学協会向けにWebサービスを開発、提供するテックカンパニーだ。学会運営や会員管理を効率化するプラットフォームやオンラインの学術雑誌への論文投稿、審査に特化したサービスを提供している。これらのサービスを導入する組織は500を超え、安定した稼働が求められている。同社では、AWS上に構築されたそれらのシステムの監視にSite24x7を採用。「監視チームと開発メンバー、マネージャーはもちろん、営業やサポートメンバーまでが同じダッシュボードを見られるようになりました。これによって、DevOpsの一歩先をいく文化を目指せる」とその導入をリードした小川氏は語る。
研究者が研究に専念できる世界を目指すアトラス
株式会社アトラス
システム開発グループ DevOpsリード
小川 誠 氏
——事業やチームの体制、役割について教えてください。
小川氏 弊社は「研究者が研究に専念できる世界へ」をビジョンに掲げて、学協会向けにその運営に欠かせない「学術大会」「会員管理」「ジャーナル」のそれぞれの業務を効率化するWebサービスを開発、提供しています。
サービス名はそれぞれ「Confit」「SMOOSY」「Editorial Manager」といって、これらのサービスを500を超える学協会様にご利用いただいています。
私が所属するシステム開発グループは、お客様に提供するWebサービスの開発と運用、社員が普段利用するIT環境の管理を担っています。
弊社では70名ほどのメンバーが日常的にリモートで働いています。クラウド移行を進めてきたこともあり、社内に物理サーバーはありません。今あるのは小さなNASがひとつとネットワーク機器だけです。
そのため、社内インフラ業務としてPCのキッティング作業なども行いますが、私の仕事の8割くらいはお客様に提供しているWebサービスのインフラ運用管理業務で、監視チームのリーダーも担当しています。
監視チームのメンバーは6名で、プロダクトの開発を担当するエンジニアが兼務で担当しています。インフラ・アプリに触れているフルスタックエンジニアなので、理解やアクションが速く、いつもとても助けられています。私自身は今のサービスのインフラ構築を進めてきたこともあり、監視フローの設計も含めてサービス横断的にインフラ周りの業務を支援しています。
「監視はスキル」全員が使えるべき
——監視チームが以前抱えていた問題はどのようなものでしたか?
小川氏 私が入社したころは社内サーバーで稼働するZabbixで各種サービスを監視していました。しかし、Zabbix自体のサーバー運用工数の問題と先ほど話した社内のサーバーをなくしていこうという動きから、CTOがSaaS型のNew Relicに移行することを決めました。その導入は私が担当しました。
New Relicで使っていた監視機能は、主に
- サーバー監視
- データベース監視
- APM(アプリケーションパフォーマンス管理)
- RUM(リアルユーザーモニタリング)
- URL監視
- AWSサービス監視(RDSやApplication Load Balancerなど)
です。もちろん、モニタリング機能だけでなく、アラートのSlack通知連携やダッシュボードといったプラットフォーム機能も重要でした。
これらの機能を使って順調に運用していたのですが、導入から5年くらい経った頃に、New Relicのライセンス体系がユーザー数に応じたものに変わりました。これにより、監視チームにとって重要と考えていた環境が作れなくなってしまいました。
——その「監視チームにとって重要な環境」とはどのようなものですか?
小川氏 O'Reillyの書籍の「入門 監視」にあるように、「監視はスキル」と考えているので、メンバー全員が監視ツールを使えるようになって、成長していける環境づくりが重要と私は考えているんです。
ライセンス体系が変わったことで、メンバー分のライセンスを用意しようとするとこれまでの何倍ものコストがかかってしまうため、それが叶わなくなりました。最後はユーザーを2人に絞って運用していました。
そのため、他に良いツールはないかと探し始めたところ、メンバーのひとりが見つけてきたのがSite24x7でした。
——先ほど伺った機能はすべて代替できたのでしょうか?
小川氏 はい、すべて代替できました。
お試し期間にそれを実際に確認できたことが今でも印象に残っています。ゾーホーさんのお試し期間は30日なので長いですよね。
その間にSite24x7でできること・できないことを把握し、足りない部分をどう補うかを検討できました。その結果、これまでのツールと同じ機能が満たせることや、納品物についても今と同じものが作れることを、CTOやチームメンバーに実際の画面を見せながら報告・共有できました。
Site24x7の標準機能で対応できない要件については、Site24x7 APIを使い対応しました。運用の手間が若干増えたものの、許容できるレベルです。
AWS EC2スポットインスタンスを日次で起動・終了するという運用をステージング環境で行っているのですが、そのための対応です。(詳細は後述)
——サポートも活用されましたか?
小川氏 はい。今までの使い慣れたツールとは異なるツールなので、どうしても使い始めはたくさん疑問が出てきます。お試し期間にも関わらず、技術的な質問にも丁寧に、それこそ開発者の方も巻き込んでいただきながら答えていただけました。
こういうサポート体制なら今後使いこなしていけるだろうと思えました。
DevOpsの一歩先を目指せる
——そして、全員が使える環境をつくれたということですね?
小川氏 はい。ただ、得られたことはそれだけではありませんでした。
ユーザー課金ではなくなったことで、監視チームと開発メンバー、マネージャーはもちろん、営業やサポートメンバーまでが同じダッシュボードを見られるようになりました。これによって、DevOpsの一歩先をいく文化を目指せるようになると考えています。
このような将来のビジョンを描けたことがSite24x7を導入する決め手になったと言っても過言ではありません。
——それはどのような効果をもたらすのでしょうか?
小川氏 営業やサポートメンバーも日常的にプロダクトを触っているので、システムの異変に遭遇することがあります。
これまでは、問題が自分の環境にあるのかプロダクト側にあるのか確信が持てないまま、周囲のメンバーや開発チームに確認することがよくありました。しかし、今はプロダクトの問題を可視化したダッシュボードがあり、それは全員が見られるものなのでサポートも開発も同じダッシュボードを見ながら、対応できるようになりました。
同じデータを見ながら議論できるので、部門間の連携もしやすくなり、ひいてはお客様に対する会社の対応スピードも上がると考えています。
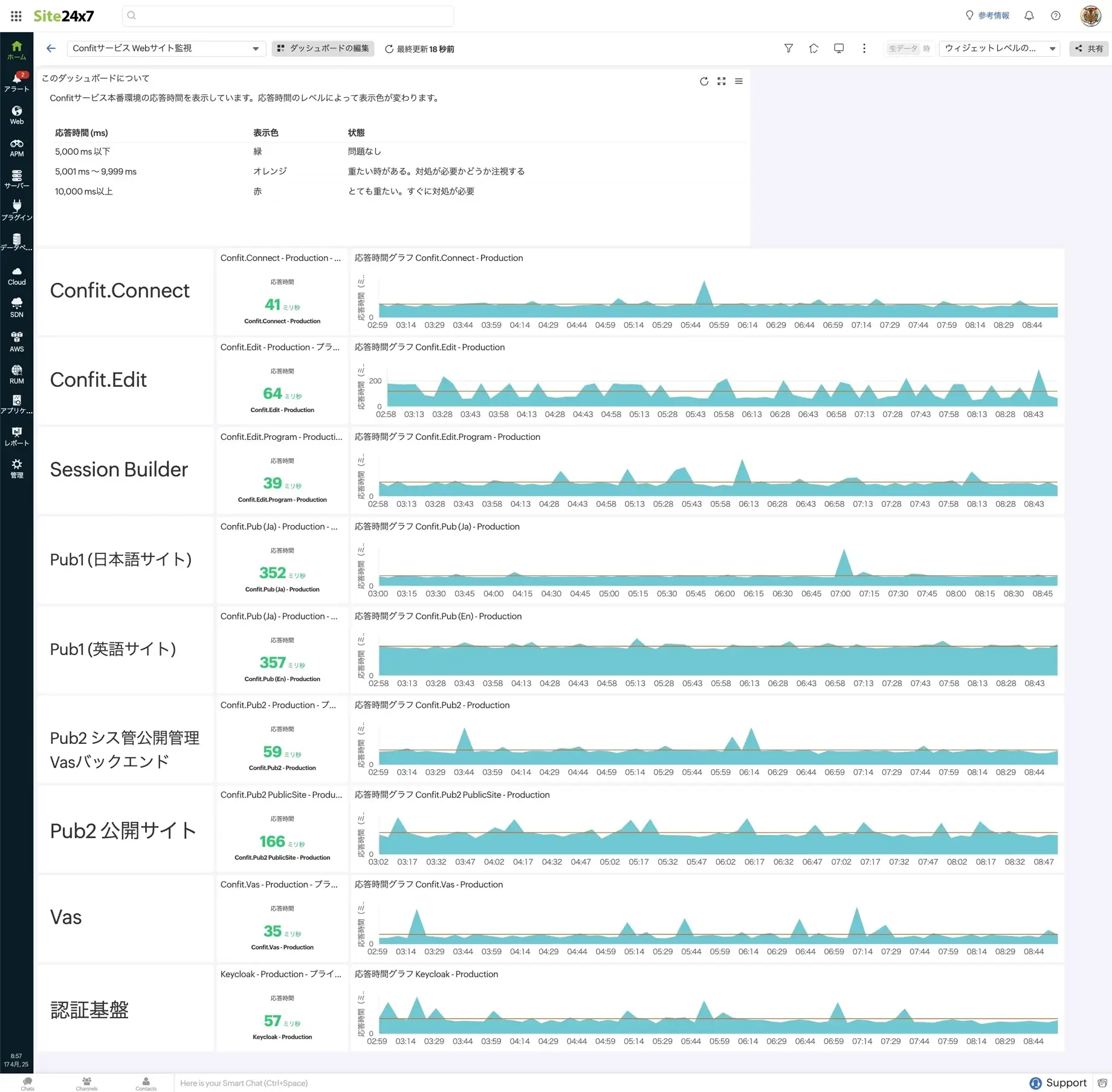
営業・サポートメンバーが見るダッシュボード
数字の色で問題の有無を直感的に把握できるようになっている。
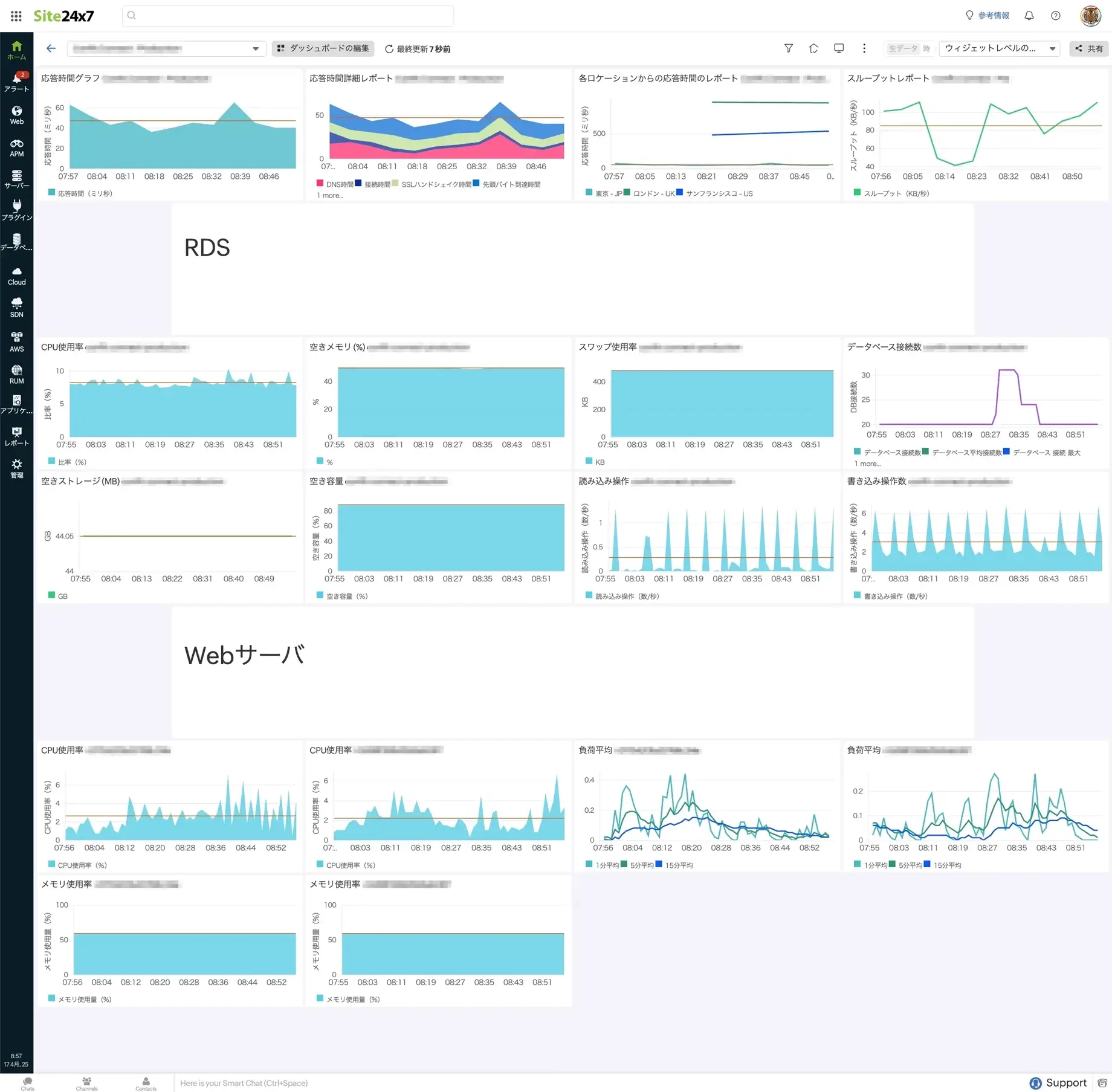
監視チームメンバーが見るダッシュボード
重要な監視項目に絞って時系列グラフを表示することで原因の特定がしやすくなっている。
監視の肝はアラートの最適化
——導入時に工夫したことを教えてください。
小川氏 監視ツールを導入する時に最も注力することのひとつが、アラートの最適化です。本当に対応が必要な時だけアラートが上がるようにするのが理想です。そのために対応したことがいくつかあります。
例えば、意図的にサーバーを停止・削除した時にダウンアラートが上がってしまうと「これは無視して大丈夫です」と担当者が監視メンバーにその都度報告することになり、ひとつひとつは小さいながらも無駄な工数になってしまいます。
私たちのプロダクトは定期的にメンテナンス作業を実施しているものもあるのでその期間はSite24x7のスケジュールメンテナンス機能を使い、監視対象から外すことで余計なアラートが上がらないようにしています。プロダクト単位で対象サーバーを監視グループにまとめて、グループ単位でスケジュールメンテナンスを設定しています。
先ほど話したEC2スポットインスタンスの日次での起動・終了の対応も工数削減の工夫のひとつです。
インスタンス起動時にはEC2の起動テンプレートを使い、自動でSite24x7のエージェントをインストールし、その際に監視グループ・設定ルールを指定しています。
インスタンスの終了時には、監視グループ単位で設定したメンテナンス期間にインスタンス終了時刻を含めるようにして、サーバーDOWNのアラートが出ないようにします。その後、AWS LambdaからSite24x7 APIを実行し、Site24x7のサーバー監視を削除します。
実際の運用作業では、Webサイトの応答時間のアラートのみで対応が必要になるということはなく、それと同時にサーバーのメモリ使用率が高止まりしていたら対応する、ということもあります。複数アラートの組み合わせで判断することもあるので、「アラート=即対応」ではなく、システムの状態を知るための何らかのアラートは日常的に出ています。
なので、重要なアラートを見つけやすくする工夫もしています。具体的には、アラート表示内容のカスタマイズです。
アラートはすべてSlackのチャネルに流しています。Site24x7の場合、Amazon EventBridgeとも連携できるので、Site24x7と連携したEventBridgeからSlack通知用のLambdaを起動し、通知内容をカスタマイズできるところも気に入っています。
というのも、デフォルトのアラートだと1つあたりの情報量が多く、アラートが増えた際に重要なものを見落としやすくなってしまいます。自分たちにとって必要な情報だけに絞ることで見やすくしています。

Site24x7のアラートが並んだSlackチャネル
必要十分な情報が表示されるようカスタマイズされている。
——アラートの最適化ということは、しきい値も重要だと思うのですが、どうやって決めていますか?
小川氏 おっしゃる通りです。
サーバーのメモリ使用率ひとつとってもプロダクトが異なればシステムの特性が異なるので、適切なしきい値も異なります。別の監視メトリクスとの組み合わせが必要になる場合もあります。
しきい値を定める必要のある監視を追加したら、はじめは過去にトラブルがあった際の数値などから仮に定めた値を入れてトライ&エラーを繰り返します。2~4週間ほど経つ頃にはその値も落ち着いてきます。
ただ、落ち着いたらそれで終わりではありません。
監視チームでは、週1回の定例ミーティングですべてのアラートをひとつずつチェックして必要に応じてしきい値の見直しを行っています。すべてのアラートといっても日々最適化しているので膨大な数をチェックするわけではありません。
こういったことを欠かさず定期的に実施することが重要だと感じています。
——大変勉強になります。Site24x7はAIエンジンでこのアラートの最適化を自動化することを目指しているのでご期待ください。
小川氏 そうなんですね。楽しみにしています。
次はサービス稼働状況をお客様に公開
——システムの応答遅延でお客様からお問い合わせを受けることは今もあるのでしょうか?
小川氏 今はほとんどありません。
手前味噌ですが、それも監視ツールでアラートを最適化して、先回りでプロダクト側の対応をできるようになってきたということだと思います。
今は次のステップとして、万が一そうなり得る事態が起きても、誰よりも先に、監視チームから発信・共有することを目指しています。
また、営業やサポートメンバーが見ることのできるダッシュボードに加えて、Site24x7のステータスページ公開機能のStatusIQを導入予定です。お客様がリアルタイムにサービスの稼働状況を確認でき、問題が起きた際に通知を受け取れるようにする予定です。
——ありがとうございます。最後に、Site24x7をご検討中の読者の皆さまにアドバイスをお願いします。
小川氏 今導入されている監視ツールのコストにお悩みの方は、Site24x7をお試しいただくと良いと思います。
先ほども申し上げた通り、私たちのケースでは、以前の監視ツールと標準機能で比較すると、以前のツールより運用の手間が少し増えることや、運用方法を変えないといけないということがわかりました。
それでも、Site24x7はAPIを提供しているので、多少のコーディングと運用方法の工夫でその差を埋められることもわかりました。
コスト面だけでなく、目指すべきチームの土台を得られたことが大きな価値だと思うので、試さない手はないと思います。